The Akida Development Environment (MetaTF) is a complete machine learning
framework enabling the seamless creation, training, and testing of neural
networks on the Akida Neuromorphic Processor Platform. MetaTF includes an
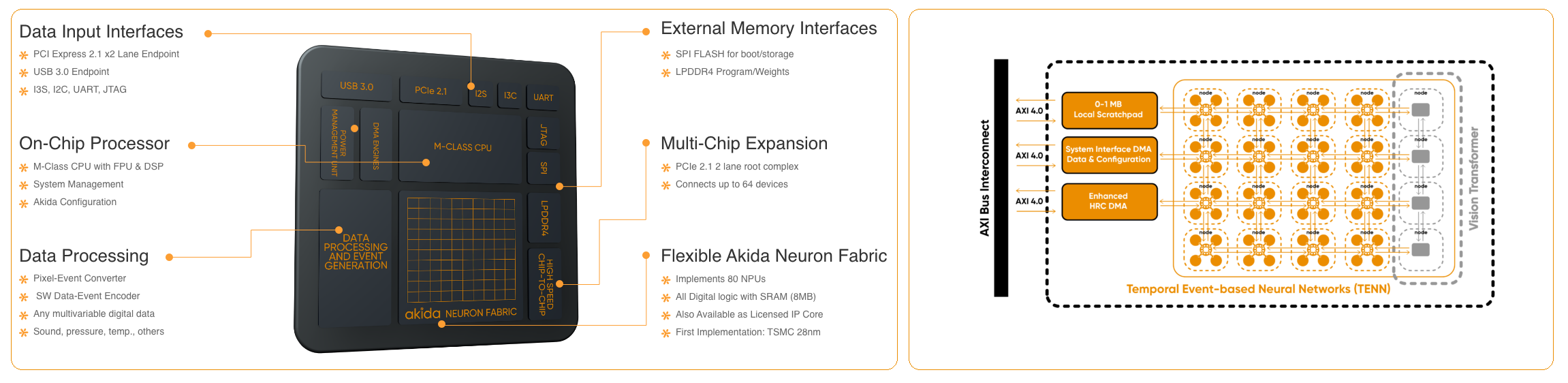
Akida Neuromorphic Processor IP
simulator for execution of models in addition to Akida hardware implementations
such as the AKD1000 reference SoC.
Inspired by the Keras API, MetaTF provides a high-level
Python API for neural networks. This API facilitates early evaluation,
design, final tuning, and productization of neural network models.
AKD1000 reference SoC (left), Akida 2nd Generation IP (right)
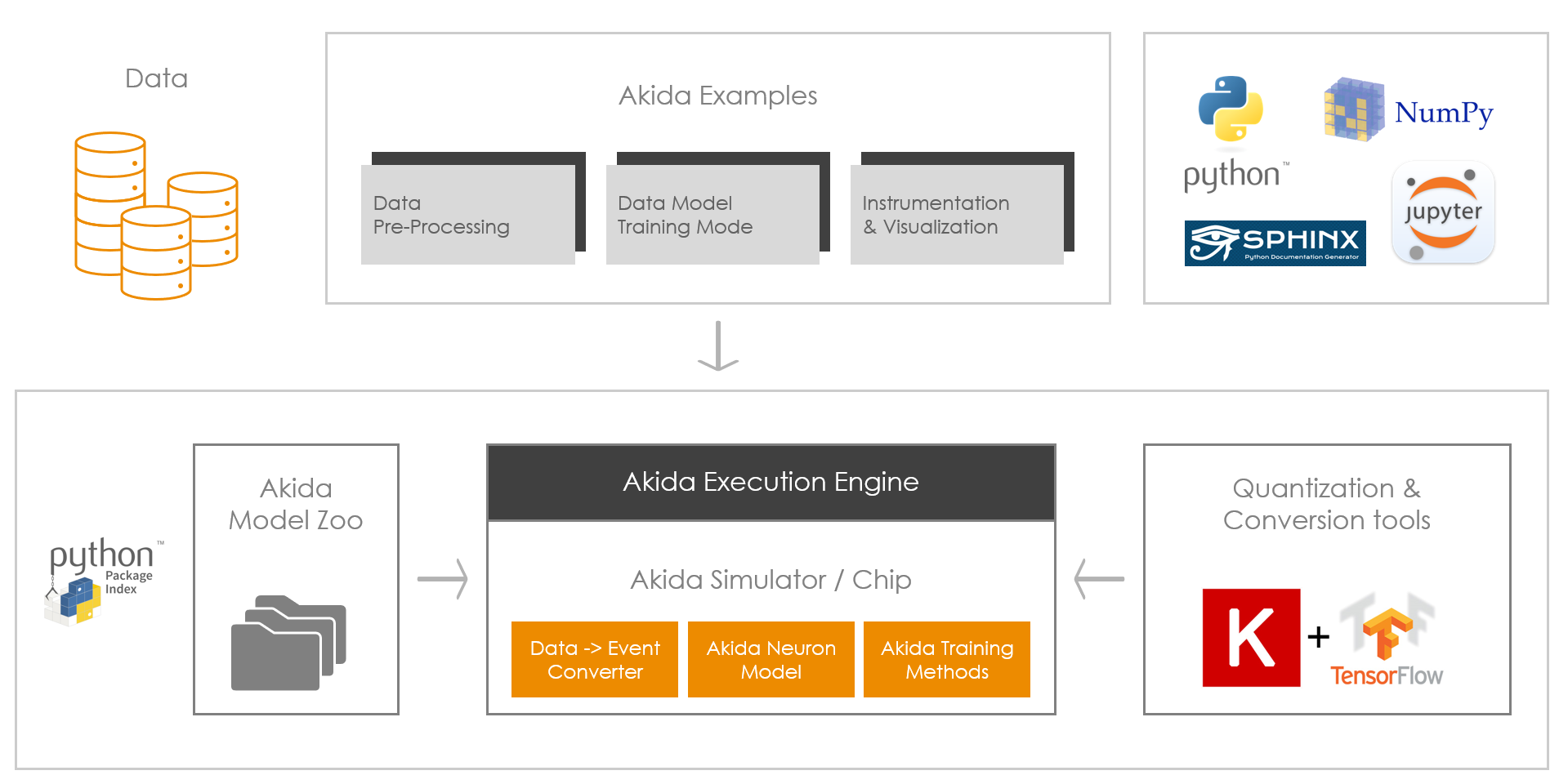
MetaTF is comprised of four Python packages which leverage both the
TensorFlow (through
TF-Keras) and ONNX
frameworks, and are installed from the PyPI repository via pip command.
The four MetaTF packages contain:
a Model zoo (akida-models) to
directly load quantized models or to easily instantiate and train Akida
compatible models,
a quantization tool (quantizeml)
for quantization of models using low-bitwidth weights and outputs,
a conversion tool (cnn2snn) to convert
models to a binary format for model execution on an Akida platform,
and an interface to the Akida Neuromorphic Processor (akida)
including a runtime, a Hardware Abstraction Layer (HAL) and a software
backend. It allows the simulation of the Akida Neuromorphic Processor and
use of the AKD1000 reference SoC.
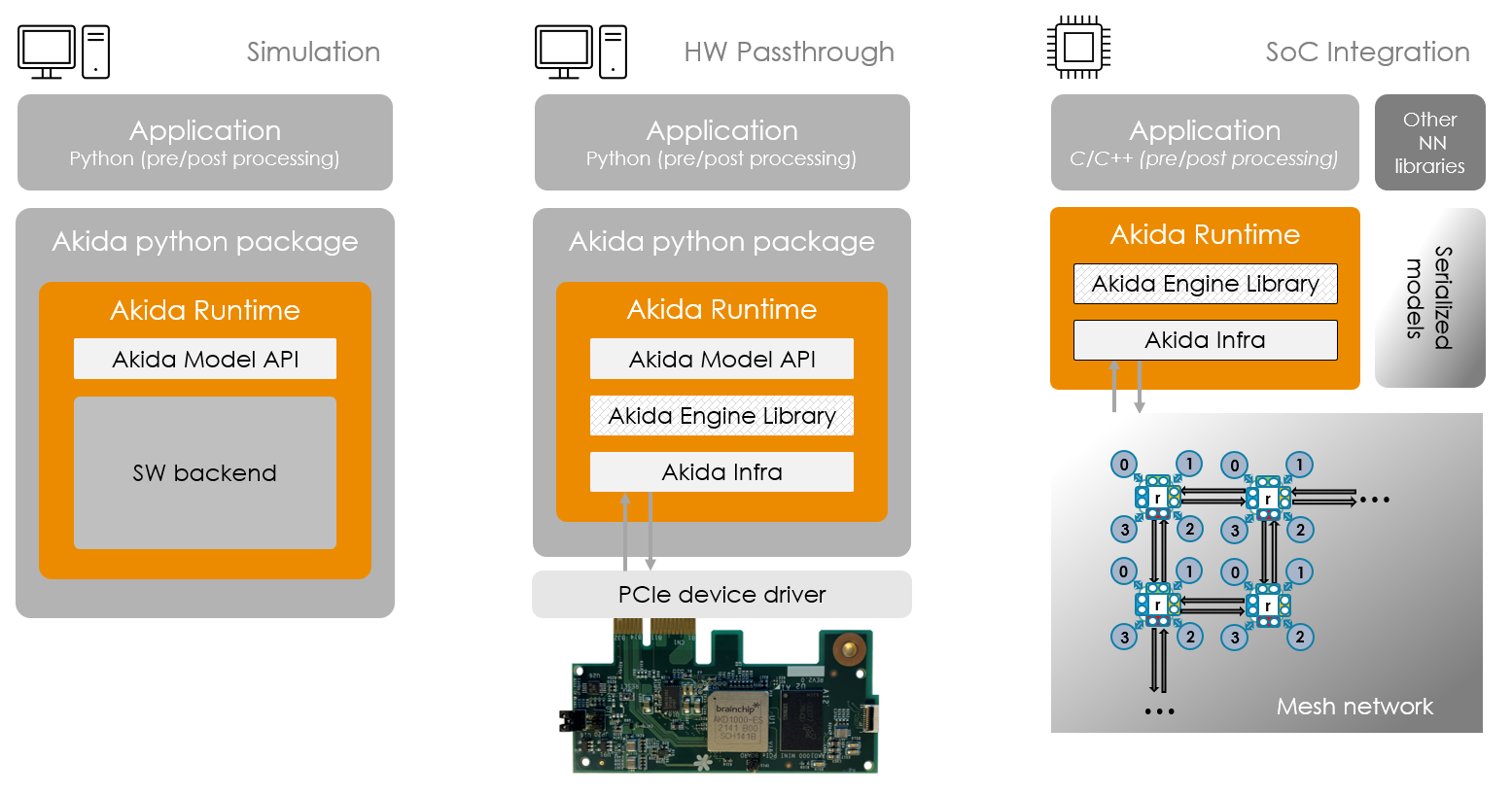
The Akida package introduced above allows one to simulate the Akida Neuromorphic
Processor IP without the need for any hardware. Furthermore, the interface to the
Akida runtime enables seamless integration with Python-based, machine learning
frameworks for easy prototyping with the Akida Neuromorphic Processor IP.
It includes:
the Akida model API - a library supporting the native development of Akida models,
the inference of instantiated models, their serialization (program sequences)
and their mapping for a targeted hardware device,
a simulator (software backend) - a CPU implementation of the Akida Neuromorphic
Processor IP,
and the Akida Engine Library - a C++ library supporting the instantiation of model
programs produced by the model library on actual hardware devices and inference on
programmed devices.
The examples section includes tutorials and examples to easily
get started with Akida technology. This section illustrates the use of Akida technology
on a variety of inference and incremental, on-device learning applications.
Warning
While the Akida examples are provided under an
Apache License 2.0,
the underlying Akida library is proprietary.